2024-04-16 | 周刊王
業內專家用8萬字長文測試各家的模型,發現聯發科在繁體中文的表現最好。(圖/翻攝自ihower部落格、各家官網)
![繁中守護者2/母湯是一種清湯?專家測試8萬字資料Breeze運算跑第一「OpenAI不友善」]()
GPT-4在中文領域的回答仍有侷限性。(圖/記者黃耀徵攝)
![繁中守護者2/母湯是一種清湯?專家測試8萬字資料Breeze運算跑第一「OpenAI不友善」]()
聯發創新基地在台大、倫敦、劍橋都有據點,一起研究AI。(圖/翻攝自聯發創新基地官網)
繁中守護者2/母湯是一種清湯?專家測試8萬字資料Breeze運算跑第一「OpenAI不友善」
[周刊王CTWANT] 全世界最強繁中大型語言模型LLM問世,「MR BreeXe針對中文特殊情境優化,所以速度提升1倍,布建成本下降一半。」聯發創新基地資深技術經理陳宜昌告訴CTWANT記者。
目前全世界有中文參數的LLM模型,包括歐美科技業者投資OpenAI的ChatGPT、Google的Gemini,Facebook母公司Meta推出的LLaMA,中國有百度的「文心一言」等,但大多以簡體中文的內容為主。
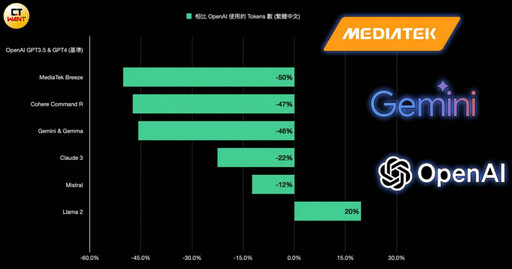
究竟聯發科推出的繁中LLM功力如何?業內專家ihower用數發部的政府報告、管理學講義共8萬多字做壓力測試,結果發現聯發科在Tokenizer (分詞器)上的調整相當「有感」。
ihower表示,一樣的文本,若能用比較少的 Tokens 數來表示,推論速度會比較快、成本也會比較划算,畢竟計價也是用Tokens數計算的。
「以OpenAI為基準,聯發科的Breeze大約節省50%的Tokens數、運算更快,而Google Gemini大約節省46%,Llama 2甚至比OpenAI差、多增加了20%。」「OpenAI的Tokenizer對繁體中文真的很不友善啊!」ihower說。
華碩營運長暨台智雲董事長謝明傑曾表示,OpenAI模型「大部分是英文腦,中文的腦相當少」,繁體中文資料比例低於0.1%,簡體中文資料不超過2%,但以數量來說,也相當於超過繁體中文20倍的量。
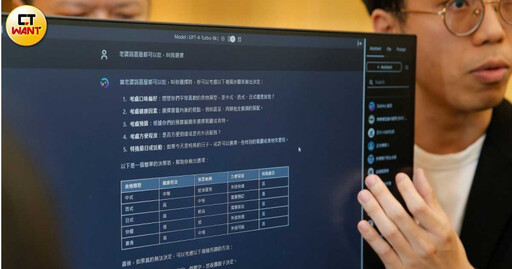
同樣是中文LLM,為何要另外做出繁體中文的版本?成功大學資工系教授黃敬群向CTWANT記者解釋,因為AI是「生成」,而且不斷「演化」,一般人不會知道內容出自哪裡,就會出現文化衝擊問題,「現在很多大學生的作業、學者論文,甚至是媒體報導的內容,用AI輔助後出現大量中國式用語與邏輯思維,而非台灣行之有年、大量專家學者累積並完成的知識與術語,但使用者可能都沒發現。」
如果不喜歡抖音文化,可選擇不看,但在AI時代,因為資料量的差異,中文世界會整個傾斜倒向中國大陸的邏輯思維,所以聯發科做繁體中文模型時「開源」公開程式碼,讓全世界的人去使用,以台灣思維為主的中文知識,才有機會進入AI時代的大腦資料來源。

除了解析中文語句的速度快,陳宜昌舉例,如果用Mixtral詢問「母湯」,他會說「是一種中國傳統的食物,通常是一種清湯或魚羹。」但在BreeXe上,就會說這是「台語的諧音梗,源自於沒關係,但在網路流行語中被用來否定、或是不正確的意思。」
聯發創新基地負責人許大山跟CTWANT記者說,會取名為BreeXe,除了致敬Mixtral原本「西北風」意思,也希望他像breeze一樣的徐徐微風、廣泛吹進大家的電腦裡,讓人有如沐春風的感覺。
一般人可能看不見、摸不著,但是這股以科技人為首的夢想與使命的風已經悄悄吹起來了。
延伸閱讀



最新生活新聞
-
-
2歲兒睡前突對空氣喊「他要跟我玩」! 媽媽一聽涼了:想搬家
(32 分鐘前) -
嘉明湖步道持續封閉 已申請山屋住宿可全額退費
(47 分鐘前) -
7縣市大雨特報!專家呼籲「雨大時離開災區」 下周颱風生成機率曝光
(51 分鐘前) -
「會呼吸的綠色停車場」 這兩座地下停車場,榮獲國家卓越建設金質獎殊榮
(52 分鐘前)